Handwritten Information Extraction in Marriage Certificates of the Population of Paris (1880–1940)
Contexte du poste
Thanks to a collaboration between specialists in machine learning and historians, the EXO-POPP project (ANR 2021) will build a database of 300,000 marriage certificates from Paris and its suburbs between 1880 and 1940. These marriage certificates provide a wealth of information about the bride and groom, their parents, and their marriage witnesses, that will be analyzed from a host of new angles made possible by the new dataset. These studies of marriage, divorce, kinship, and social networks covering a span of 60 years will also intersect with transversal issues such as gender, class, and origin.
Description
Missions
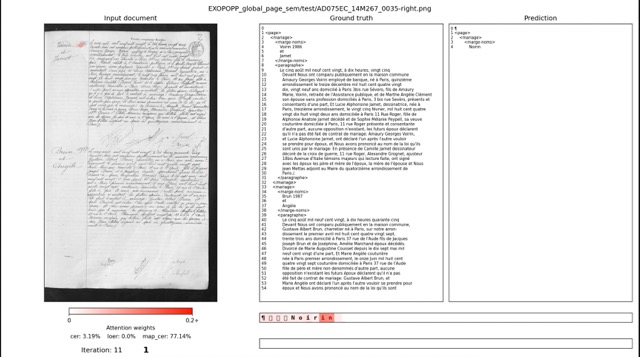
The candidate will be in charge of the development of a processing pipeline dedicated to optical printed named entity recognition (OP-NER). He/she will closely collaborate with a Ph.D. student in charge of Handwritten Named Entity Recognition (OH-NER).
1- OCR Benchmark
The Optical Named Entity Recognition task (OP-NER) is the project’s easiest task and will benefit from the latest results achieved by the LITIS team on similar problems on financial yearbooks. Images are first processed to extract every text information. This will be achieved with the DAN architecture (https://arxiv.org/abs/2203.12273) designed by LITIS which is a deep-learning-based OCR. A benchmark of DAN ( https://github.com/FactoDeepLearning/DAN) against available OCR software such as Tesseract and EasyOCR will be conducted.
2- Printed named entity recognition
The textual transcriptions will then be processed for named entity extraction and recognition. Named entity recognition is a well-defined task in the natural language processing community. In the EXO-POPP context however, we need to define each entity to be extracted more precisely to make a clear distinction between the different people occurring in the text. For example, we need to distinguish between wife and husband names, and similarly for the parents of the husband and of the wife, and so on for the witnesses, children, etc. An estimation of around 135 categories has been established. The TAG definition was made by LITIS as well as a first training dataset. Manually tagging the transcriptions has been made possible through the PIVAN web-based collaborative interface (https://litis-exopopp.univ-rouen.fr/collection/12). This platform provides in one single web interface a document image viewer, viewing and editing of OCR results and text tagging facilities for NER. PIVAN eases the annotation efforts of the H&SS trainees and allows for building the large, annotated datasets required for machine learning algorithms to run optimally. The internship candidate will oversee datasets generation and curation as per the requirement of the EXO-POPP NER task, including the handwritten datasets.
The named entity recognition task will be based on a state-of-the-art machine learning approach. We have started some experimentations with the well-known FLAIR NER library (https://github.com/flairNLP/flair). We plan to continue developing and tuning the EXO-POPP named entity recognition module using this library. The intern will oversee this task entirely.
3- End to end Printed Named Entity Recognition
Finally, we will explore an end-to-end architecture for OP-NER using the DAN. In close collaboration with Ph.D. student the intern will compare different architecture and modeling schemes of End-to-end OP-NER recognition.
Skills :
• General software development and engineering, Python
• Machine Learning, Computer vision, Natural Language Processing
• Ability to work in a team, curious and rigorous spirit
• Knowledge in web-based programming is a plus
Fichiers associés
Comment postuler ?
Positions: 6-month internship, with possible continuation as a research engineer for 12 months. Time commitment: Full-time
Duration of the contract: March 1st 2023 - August 31st 2023
Contact: Prof. Thierry Paquet, Thierry.Paquet@univ-rouen.fr
Location: LITIS, Campus du Madrillet, Saint Etienne du Rouvray